
Vous vous êtes déjà demandé comment fonctionne la mémoire cache et pourquoi est-elle si importante que cela dans votre système ? Ça tombe bien, on fait le point…
Utilisée depuis plusieurs décennies comme mémoire centrale, la DRAM n’a pas vu ses performances augmenter aussi vite que celle des processeurs, avec en particulier une progression relativement lente, voir une stagnation des latences… Il a donc rapidement fallu trouver une solution pour pouvoir continuer à gaver le processeur avec toujours plus de données sans qu’il passe son temps à attendre que la RAM daigne bien lui répondre : l’ajout d’un cache, une petite zone de mémoire très rapide qui fait le lien entre le processeur et la mémoire de travail.
Le cache du CPU est le plus souvent constitué de mémoire SRAM (Static RAM), une mémoire entièrement constituée de transistors (en général, 6 transistors par bits), moins dense (et donc plus coûteuse) que la DRAM, mais capable de réagir bien plus vite (avec des latences de l’ordre de la nanoseconde au lieu de plusieurs dizaines de ns pour les DRAM) et ne nécessitant pas de rafraichissement des données, qui sont conservées tant que la puce est alimentée.
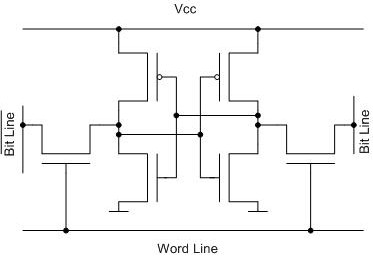
Un peu d’histoire…
Dans le monde du x86, le cache est d’abord apparu sous forme de puces amovibles placées directement sur la carte mère.

À partir du 486 (et de certaines variantes non Intel du 386), un premier niveau de cache a été intégré directement dans le CPU, tout en gardant la possibilité d’ajouter un second niveau de cache sur la carte mère.

Avec les CPU en slot (Pentium II, Athlon), ce second niveau de cache a été intégré dans le package du processeur, d’où le format sous forme de carte, et est monté en fréquence (la moitié de la fréquence du CPU).
Enfin, les générations suivantes (Pentium III, Athlon XP) ont intégré le cache directement dans le die du processeur, permettant de le faire fonctionner à pleine fréquence et de revenir à un format socket.
Fonctionnement du cache en lecture
Dans ses grandes lignes, le fonctionnement du cache est relativement simple. Quand le processeur demande une donnée présente en mémoire, identifiée par son adresse, la demande est transmise au contrôleur du cache, qui va vérifier si la donnée en question est présente dans le cache. Si oui (« cache hit »), il la renvoie directement au processeur, sinon (« cache miss ») il va relayer la demande au contrôleur mémoire.
Mais comme le processeur accède souvent à plusieurs mots mémoire contigus, lorsque le contrôleur du cache va réclamer des données au contrôleur mémoire, il va en fait demander plusieurs mots d’un coup : le cache fonctionne avec une unité de base qui est la « ligne de cache », qui fait généralement quelques dizaines d’octets (64 sur les CPU Intel actuels par exemple) et à chaque fois qu’il charge une donnée, il charge en fait toute une ligne, maximisant les chances que la prochaine donnée demandée par le CPU soit présente dans le cache.
De plus, pour que les performances du cache soient maximales, une même adresse mémoire ne peut généralement correspondre qu’à un petit nombre de lignes de cache. Pour ce faire, chaque adresse mémoire (64 bits en x86-64) est découpée en trois parties :
- Block offset : les derniers bits de l’adresse, qui vont donner la position de la donnée dans la ligne de cache. Avec une ligne de cache de 64 octets, le block offset correspond donc aux 6 derniers bits de l’adresse (64 = 2^6).
- Index : le groupe de lignes de cache dans lequel cette adresse peut être recopiée. La taille des groupes est l’associativité du cache. Si par exemple chaque adresse peut être recopiée dans 2 lignes, on dit que le cache est « 2-way associative ». La longueur de l’index dépend donc de la taille du cache (nombre de groupes de lignes) et de son associativité. Par exemple, sur un processeur Haswell, avec un cache L2 8-way de 256 Ko, l’index fait 9 bits (4096 lignes, soit 512 groupes). Quand une adresse peut être placée n’importe où dans le cache (on parle alors de cache « fully associative »), l’index n’existe pas.
- Tag : le reste de l’adresse.
Une ligne du cache est pour sa part constituée, en plus des données en elle-même, du tag et d’un groupe de « flags », qui donnent des informations sur l’état des données dans le cache. Il y en a généralement deux : « valid » qui indique si les données présentes dans le cache sont bien des données qui ont été lues en mémoire, « dirty » qui indique s’il y a eu une écriture dans le cache depuis la dernière lecture.
Ainsi, pour déterminer si une donnée est présente en cache, il suffit à partir de son adresse de déterminer le groupe de lignes dans lequel elle doit éventuellement se trouver puis de lire le tag stocké dans chacune des lignes du groupe. S’il correspond au tag de l’adresse, la donnée est en cache, sinon il faudra aller la chercher au niveau supérieur.
Du fait de ce mode de recherche, plus l’associativité est faible, plus la recherche dans le cache est rapide, puisqu’il y a moins de lignes à tester. L’associativité faible laisse par contre moins de souplesse dans la gestion des données présentes en cache : lorsqu’une ligne doit entrer dans le cache, le choix de lignes à faire ressortir pour libérer la place est plus faible.
Pour améliorer les performances de la recherche, les tags des lignes de cache sont parfois stockés dans un module mémoire spécifique, plus rapide que le reste du cache.
Fonctionnement du cache en écriture
Pour les écritures, le fonctionnement est très similaire. Au lieu d’envoyer directement sa requête d’écriture au contrôleur mémoire, le processeur l’envoie au contrôleur du cache, qui va écrire les données dans la ligne de cache correspondante (en chargeant préalablement l’ensemble de la ligne à partir de la RAM si elle n’est pas encore chargée).
Le cache peut par contre adopter principalement deux stratégies différentes pour la gestion des écritures dans la RAM :
- Write-through : chaque fois qu’une donnée est écrite dans le cache, l’écriture est immédiatement reportée vers la RAM.
- Write-back : lors d’une écriture en cache, la ligne est simplement marquée « dirty », et la recopie en RAM est effectuée plus tard.
La stratégie write-back est en général plus performante, en réduisant les écritures en mémoire quand plusieurs écritures sont effectuées successivement dans la même ligne, mais peut ralentir les lectures : si une nouvelle ligne de cache doit être chargée à la place d’une ligne « dirty », il faut d’abord effectuer l’écriture en mémoire.
Dans un environnement multi-cœur où les cœurs ont une portion de cache dédié ou semi-dédié, il faut de plus que les cœurs communiquent entre eux lors des écritures : quand le contenu d’une adresse est modifié, tous les cœurs doivent être notifiés pour qu’ils invalident la ligne correspondante s’ils l’avaient en cache.
Dans le cas d’une stratégie write-back, cette communication doit aussi se faire sur les lectures : lorsqu’un cœur veut charger une ligne à partir de la RAM, il doit s’assurer qu’il n’y a aucune écriture en attente pour cette ligne dans les caches des autres cœurs.
Les différents niveaux de cache
Sur la plupart des CPU d’aujourd’hui, on trouve plusieurs niveaux de cache. Ce découpage répond à la nécessité de faire un compromis entre performances, capacité et coût. De manière général, plus un cache est volumineux, plus sa latence est élevée (notamment du fait d’une associativité généralement plus large sur les gros caches), mais plus son taux de hit est élevé.
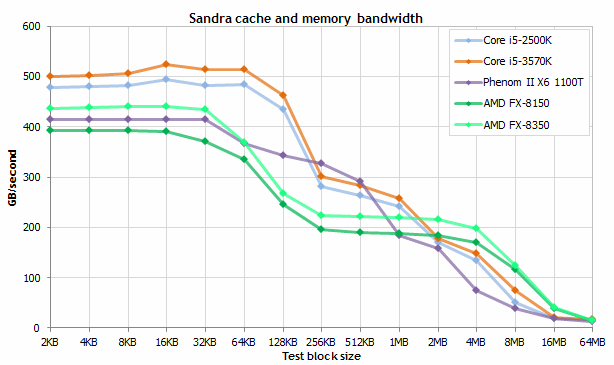
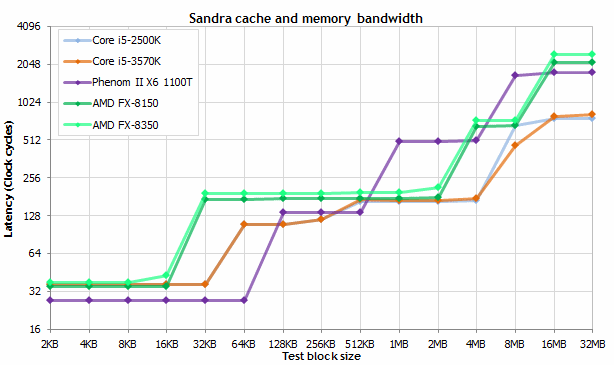
Les performances des différents niveaux de cache
On trouve donc en général un très petit cache de premier niveau très rapide, n’excédant pas quelques dizaines de Ko et souvent divisé en deux, un cache d’instruction (L1I) et un cache de données (L1D). Cette séparation permet à deux unités du processeur d’accéder simultanément au cache : le décodeur d’instruction utilise le cache L1I tandis que les unités de calcul utilisent le L1D. Un processeur Intel Haswell dispose de 32 Ko de L1I et de 32 Ko de L1D pour chaque cœur, tous deux en 8 way, tandis que chaque cœur d’un AMD Vishera embarque 16 Ko de L1D 4 way et chaque module CMT (2 cœurs) embarque 64 Ko de L1I 2 way. En général, toutes les déclinaisons d’une même architecture embarquant la même quantité de L1, celui-ci étant fortement intégré avec le cœur d’exécution.
Quasiment tous les processeurs modernes embarquent également un cache de second niveau et, de plus en plus souvent, on trouve également un cache L3, en particulier sur les architectures multi-cœur (avec dans ce cas en général un L2 dédié à chaque cœur ou partagé entre un nombre réduit de cœurs et un L3 partagé entre tous les cœurs). La capacité de ces caches est souvent une des variables d’ajustement entre les différents modèles d’une gamme.
Du côté du x86, les premiers multi-cœurs ont été accompagnés de volumineux caches L2 partagés, atteignant plusieurs Mo (jusqu’à 6 Mo par paire de cœurs sur les Core 2 par exemple), puis les fondeurs sont revenus à des capacités plus petites, mais dédiées et complétées par un cache L3 partagé. Ainsi, on trouve aujourd’hui sur les processeurs Haswell 256 Ko de L2 par cœur et 2 à 8 Mo de L3, tandis que Vishera est doté de 2 Mo de L2 par module et 4 à 8 Mo de L3 partagé. Sur les processeurs plus haut de gamme, le cache peut atteindre plusieurs dizaines de Mo (37.5 Mo sur les plus gros Xeon, 80 Mo sur les Power7+ d’IBM…).
Beaucoup plus rarement, on peut même trouver un quatrième niveau de cache. C’est le cas notamment sur les processeurs Haswell avec IGP GT3e. Ceux-ci embarquent en effet dans le package une puce de mémoire eDRAM de 128 Mo, prévue avant tout pour améliorer les performances de l’IGP, mais qui se comporte en pratique comme un cache L4 et peut en théorie bénéficier aussi au CPU (en pratique les gains pour le CPU sont négligeables). Son comportement est toutefois un peu particulier, puisqu’il ne charge jamais de données directement à partir de la mémoire. Il se contente en fait de récupérer des données lorsqu’elles sont retirées du cache L3 pour être remplacées par d’autres (on parle de « victim cache »).
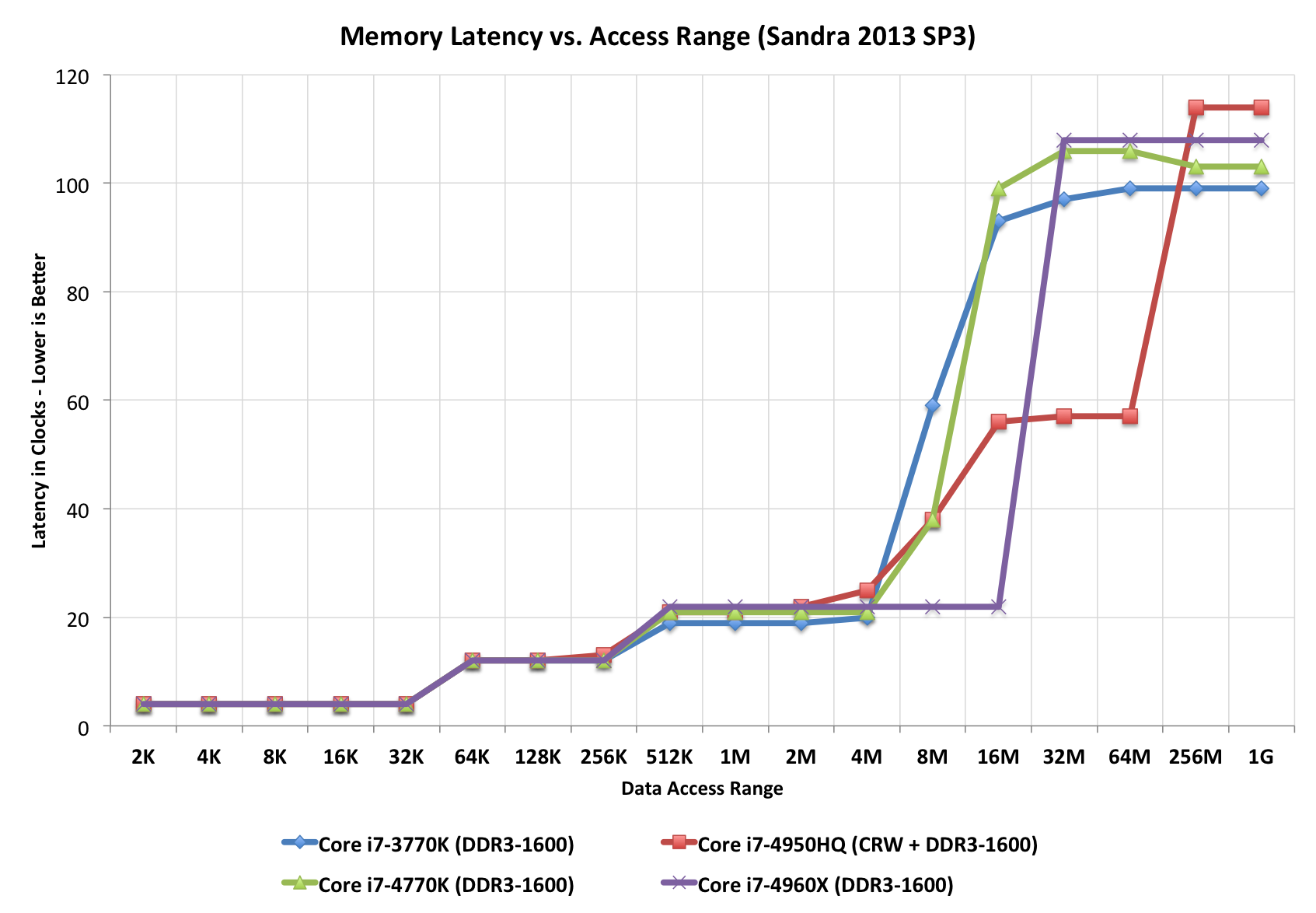
Lorsqu’il y a plusieurs niveaux de cache, les différents niveaux peuvent être inclusifs (les données présentes dans le cache à un niveau sont toujours présentes au niveau supérieur), exclusifs (les données présentes à un niveau ne sont pas présentes dans les autres niveaux) ou ni l’un ni l’autre (une donnée peut être présente à plusieurs niveaux, mais pas obligatoirement). La stratégie exclusive permet d’augmenter le taux de hit en maximisant la capacité totale effective du cache, tandis que la stratégie inclusive permet d’avoir des tailles de lignes différentes en fonction des niveaux et d’accélérer les opérations de synchronisation. Par exemple, quand un composant externe au processeur modifie une donnée en mémoire et qu’il faut donc l’invalider si elle est dans le cache, il n’est pas nécessaire de vérifier sa présence à tous les niveaux, si elle n’est pas présente au plus haut niveau elle ne sera pas non plus présente aux niveaux inférieurs.
En plus de ces caches « génériques », un processeur contient également divers caches spécialisés, qui sont dédiés à certaines tâches, comme par exemple la TLB (Translation Lookaside Buffer), qui est utiliser par l’unité de gestion mémoire (MMU) pour accélérer la conversion des adresses mémoire virtuelles (chaque processus dispose en général de son propre espace d’adressage virtuel, pour limiter les risques qu’un processus puisse accéder à la mémoire d’un autre) en adresses physiques. Comme pour le cache générique, la TLB peut éventuellement être divisée en plusieurs niveaux.
Il n’y a pas que le cache dans la vie…
Les perfectionnements successifs dans le fonctionnement du cache et les grandes capacités des caches d’aujourd’hui permettent d’atteindre des taux de miss très faibles. Les processeurs ont donc été petit à petit dotés de technologies permettant d’éviter que le processeur se tourne les pouces pendant qu’il attend les données suite à un cache miss.
Parmi elles, on notera principalement :
- l’exécution « out of order » : lorsqu’une instruction est en attente de données, le processeur commence à exécuter les instructions suivantes qui ne dépendent pas du résultat de l’instruction bloqué.
- le « simultaneous multithreading » (Hyper-Threading chez Intel) : un cœur physique dispose de plusieurs pipelines d’exécution. Ainsi, si l’un des pipeline est bloqué, un autre peut continuer à s’exécuter.
Notez que ces technologies ne se limitent pas à compenser les cache miss, elles permettent généralement aussi des gains de performances indépendamment des cache miss, par exemple en permettant une meilleure utilisation des différentes unités de calcul du processeur (exécution parallèle de plusieurs instructions utilisant des unités différentes).
Vaut mieux en avoir beaucoup alors.
Il aurait été simpa de citer le pentium pro dans la section « Un peu d’histoire… » http://commons.wikimedia.org/wiki/File:Pentiumpro_moshen.jpg
Ce n’est pas le nombre de cache qui compte le plus mais l’accès à celui-ci. Plus les latences son grande et plus le nombre n’avantagera pas le processeur. Ce qui est l’un des défauts des FX d’AMD.
Oui et plus encore : la taille des caches, s’ils sont partagés entre plusieurs cores, leur latence, leur nombre de (pre)fetchs faisables en parallèle…
Très intéressant !
même si j’ai besoin d’1gr de paracetamol….