
Cette semaine dans « La Question Technique », on fait le point sur la Random Access Memory, qui n’est bien sûr pas que le titre du dernier album des Daft Punk…
La DRAM est une mémoire RAM, pour Random Access Memory, c’est-à-dire une mémoire dont tous les éléments peuvent être accédés dans un ordre totalement aléatoire, avec un temps d’accès constant, contrairement par exemple à un disque dur, où les accès séquentiels sont bien plus rapides que les accès aléatoires.
En pratique, les temps d’accès ne sont plus absolument constants sur les DRAM d’aujourd’hui, mais les variations restent négligeables par rapport à ce que l’on peut observer sur les principaux stockages de masse.

Le D de DRAM signifie pour sa part qu’il s’agit de mémoire dynamique, c’est-à-dire qu’elle a besoin d’être régulièrement rafraichie pour conserver les données qu’elle contient, contrairement à la SRAM (statique), qui a seulement besoin d’être alimentée, mais qui est beaucoup plus coûteuse, ce qui la réserve à des usages ne nécessitant que des petites capacités (par exemple le cache des CPU). Le rafraichissement se fait en général une grosse quinzaine de fois par seconde.
Les DRAM que l’on utilise actuellement comme mémoire centrale sont des DRAM synchrones (SDRAM), c’est-à-dire qu’elles sont pilotées par un signal d’horloge et lisent les commandes et envoient des données de manière synchronisée avec cette horloge.
À quoi ça sert ?
Les utilisations de la DRAM sont multiples. Elle est notamment utilisée pour les caches des disques durs et SSD, pour la mémoire des cartes graphiques, voir comme support de stockage de masse (RAMdisk). Mais son utilisation principale reste la mémoire de travail pour nos processeurs.
Le gros de l’espace mémoire adressable directement par le processeur est en effet de la DRAM, le reste étant principalement constitué de différents buffers d’entrée/sortie permettant d’accéder au contenu d’autres mémoires (par exemple un disque dur, via les buffers du contrôleur SATA) pour les recopier dans la DRAM.
Cette mémoire de travail est essentielle au bon fonctionnement de nos machines. En effet, s’il n’y en a pas assez le processeur devra plus souvent recopier des données depuis le stockage de masse, avec pour conséquence des gros ralentissements, les temps d’accès moyens étant bien plus longs : de quelques dizaines de ns pour la DRAM on passe à quelques dizaines de µs pour les SSD, une grosse dizaine de ms pour les disques durs et une centaine de ms pour les supports optiques…
S’il peut y avoir trop peu de RAM, il est par contre plus rare d’en avoir trop, quasiment tous les systèmes actuels étant capables de tirer parti du surplus de RAM en l’utilisant comme cache pour le stockage de masse : lorsqu’un fichier est chargé depuis un support de stockage, il est ensuite conservé en RAM tant que celle-ci n’est pas nécessaire pour un autre usage, ce qui accélérera grandement sa relecture éventuelle (c’est la raison pour laquelle relancer un logiciel qui a déjà été ouvert au cours d’une session est généralement plus rapide). Passé un certain seuil, les gains de performances deviennent par contre plus faibles, le cache disque ne permettant pas forcément d’exploiter toute la mémoire disponible. Il est donc inutile de mettre des quantités énormes de RAM en comptant sur des gains de performances grâce au cache disque.
Les OS intègrent généralement des outils pour s’assurer que la quantité de mémoire est correctement dimensionnée pour votre utilisation. Sous Windows, ces informations sont disponibles notamment dans l’onglet “Performances” du “Gestionnaire de tâches”, accessible via la combinaison de touches Ctrl+Maj+Échap :
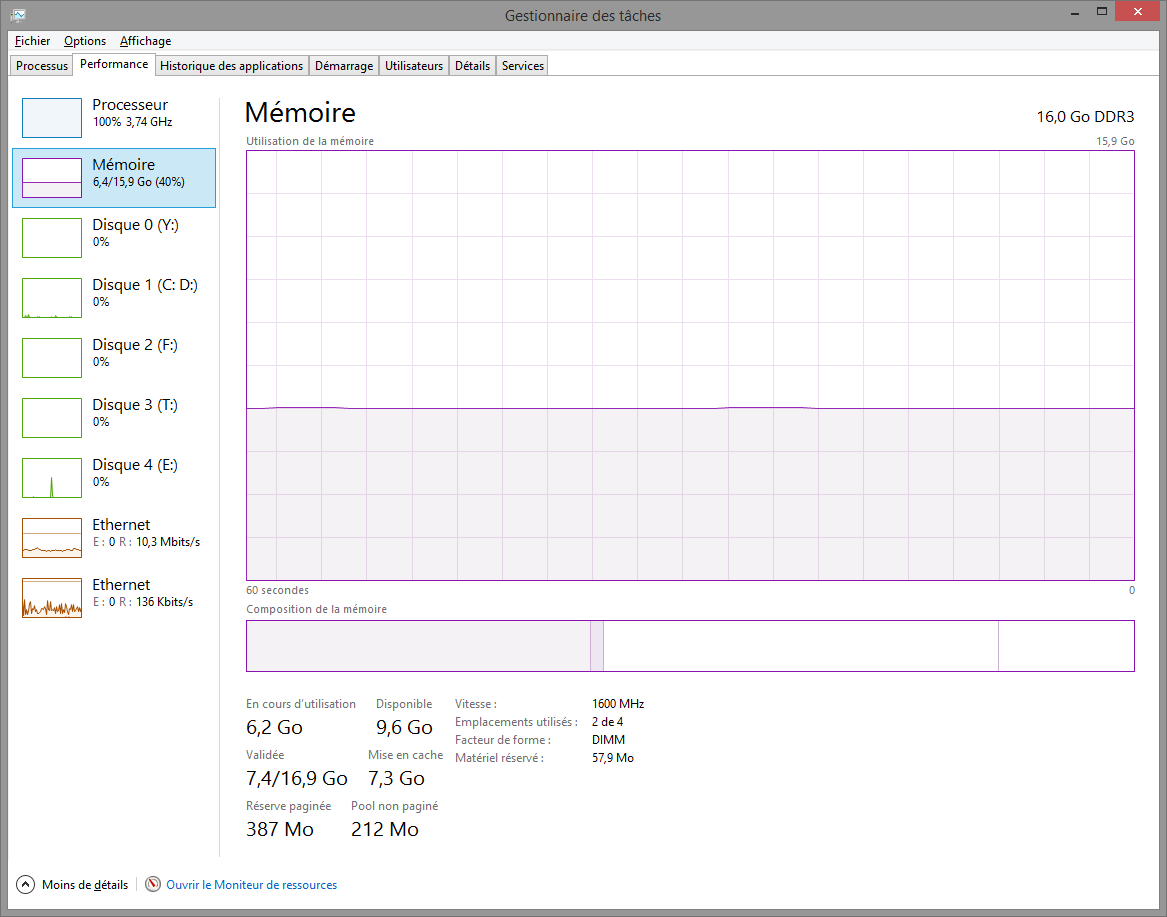 L’espace utilisé comme mémoire de travail correspond à la somme de “En cours d’utilisation” et de “Pool non paginée”, l’espace utilisé par le cache disque correspond à “Mise en cache”. La mémoire “Disponible” est pour sa part la somme de l’espace utilisé par le cache et de l’espace inutilisé. Le système considère en effet que l’espace utilisé par le cache reste disponible, puisqu’en cas de besoin supplémentaire de mémoire de travail cet espace peut immédiatement être libéré. Si votre quantité de mémoire “Disponible” est faible (moins de quelques centaines de Mo), une augmentation de la quantité de RAM est à envisager. À l’inverse, s’il y a une grande différence entre “Disponible” et “Mise en cache” est grande, inutile d’investir dans plus de RAM, le surplus ne sera pas utilisé pour le cache, qui ne parvient déjà pas à utiliser toute la RAM.
L’espace utilisé comme mémoire de travail correspond à la somme de “En cours d’utilisation” et de “Pool non paginée”, l’espace utilisé par le cache disque correspond à “Mise en cache”. La mémoire “Disponible” est pour sa part la somme de l’espace utilisé par le cache et de l’espace inutilisé. Le système considère en effet que l’espace utilisé par le cache reste disponible, puisqu’en cas de besoin supplémentaire de mémoire de travail cet espace peut immédiatement être libéré. Si votre quantité de mémoire “Disponible” est faible (moins de quelques centaines de Mo), une augmentation de la quantité de RAM est à envisager. À l’inverse, s’il y a une grande différence entre “Disponible” et “Mise en cache” est grande, inutile d’investir dans plus de RAM, le surplus ne sera pas utilisé pour le cache, qui ne parvient déjà pas à utiliser toute la RAM.
Sous Linux, vous pouvez par exemple utiliser la commande “top”, dont les lignes “Mem” et “Swap” donnent toutes les informations nécessaires :
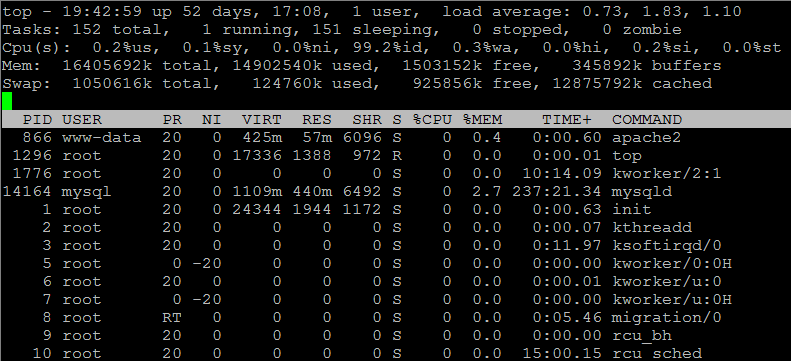 Notez par contre que contrairement à Windows, Linux ne compte pas l’espace utilisé par le cache comme de l’espace disponible. Pour savoir s’il y a un manque de RAM, il faut donc regarder trois indicateurs : “Mem free”, “Swap used” et “Swap cached”. Si “Mem free” et “Swap cached” sont faibles, la machine manque de RAM, et ce d’autant plus que “Swap used” est grand (cette valeur correspond à la quantité de données initialement en RAM qui ont été déchargées vers le disque dur pour libérer de la RAM). À l’inverse, si “Mem free” est grand, c’est que la quantité de mémoire est suffisante et que le cache disque ne parvient pas à utiliser le surplus, inutile d’investir dans de la RAM supplémentaire.
Notez par contre que contrairement à Windows, Linux ne compte pas l’espace utilisé par le cache comme de l’espace disponible. Pour savoir s’il y a un manque de RAM, il faut donc regarder trois indicateurs : “Mem free”, “Swap used” et “Swap cached”. Si “Mem free” et “Swap cached” sont faibles, la machine manque de RAM, et ce d’autant plus que “Swap used” est grand (cette valeur correspond à la quantité de données initialement en RAM qui ont été déchargées vers le disque dur pour libérer de la RAM). À l’inverse, si “Mem free” est grand, c’est que la quantité de mémoire est suffisante et que le cache disque ne parvient pas à utiliser le surplus, inutile d’investir dans de la RAM supplémentaire.
Comment ça marche ?
Schématiquement, la DRAM fonctionne avec une matrice de millions de transistors et de condensateurs, chaque cellule (stockant 1 bit) étant constitué d’un condensateur et d’un transistor (contre 4 à 6 transistors en général pour la SRAM, d’où son coût supérieur, la densité étant moindre). C’est la charge du condensateur qui conserve la valeur du bit, d’où la nécessité de rafraichir régulièrement les données, les condensateurs se vidant progressivement à cause des inévitables courants de fuite.
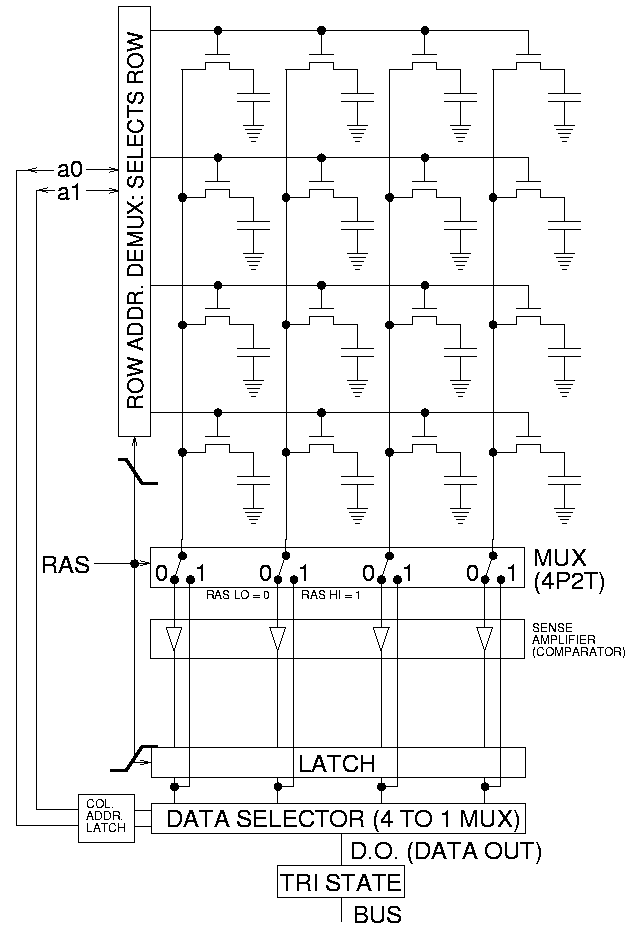
Toutes les cellules d’une ligne sont connectées à une même piste (lignes de mots, les lignes horizontales sur le schéma), tandis que les cellules d’une colonne sont connectées à une même paire de pistes (lignes de bits, les lignes verticales sur le schéma, qui n’en représente qu’une par paire).
Pour lire le contenu d’une cellule, le contrôleur commence par activer la ligne de mot correspondante (signal RAS, Row Access Strobe), ce qui a pour effet d’ouvrir tous les transistors de la ligne, et de connecter les condensateurs correspondants à l’une des lignes de bits. Si le condensateur est chargé, la tension de la ligne de bit va alors légèrement augmenter, et inversement s’il est déchargé. Un circuit va alors amplifier la différence de tension entre les deux lignes de bit, en ramenant celle de tension plus élevée jusqu’au niveau haut et l’autre jusqu’au niveau bas, ce qui permet de retrouver en sortie de ce circuit la valeur de tous les bits de la ligne sélectionnée.
Il ne reste alors plus qu’à récupérer la valeur correspondant à la colonne qu’on cherche à lire. Notez que s’il faut ensuite lire un autre bit situé sur la même ligne, le processus sera un peu plus rapide, puisqu’il n’y a plus à réaliser l’étape de sélection de la ligne de mot et d’amplification des écarts entre les lignes de bits, il suffit de changer la sélection de la colonne. Par ailleurs, en pratique ce sont en fait plusieurs colonnes qui sont lues simultanément, pour lire le nombre de bits correspondant à la largeur du bus mémoire (64 bits pour les mémoires DDR3 de nos PC).
Pour l’écriture, le processus inverse est appliqué, en forçant l’écart de tension entre les deux lignes de bits dans un sens ou dans l’autre, pour provoquer le chargement ou le déchargement du condensateur. Le rafraîchissement se fait également sur le même principe, en sélectionnant d’abord la ligne de mot à rafraîchir puis en y réinjectant l’intégralité des valeurs lues.
Les fameux timings qui sont spécifiés pour les barrettes de mémoire correspondent aux latences de ces diverses opérations impliquées dans les opérations de lecture et d’écriture. Les quatre valeurs habituellement communiquées par les fabricants sont, dans l’ordre :
- Le CAS latency, qui est le temps nécessaire pour que la valeur de sortie d’une matrice soit valide après la sélection de la colonne
- Le RAS to CAS delay, qui est le temps minimum d’attente entre la sélection de la ligne et la sélection de la colonne
- Le row precharge time, qui est le temps minimum pour désélectionner une ligne (commande Precharge) avant de pouvoir en sélectionner une nouvelle
- Le row active time est la durée minimale pendant laquelle une ligne doit rester active, mesurée entre l’envoi de la commande de sélection de la ligne et l’envoie de la commande Precharge
Plus ces latences sont faibles, plus la mémoire est performante, mais il faut toujours garder à l’esprit qu’elles sont exprimées en nombre de cycles d’horloge (pour les mémoires DDR, c’est la fréquence physique de l’horloge qui est prise en compte, d’où l’existence de valeurs non entières), et non en durée, ce qui signifie qu’un chiffre plus élevé n’est pas forcément le signe d’une plus faible latence. Par exemple, un CAS de 11 sur de la mémoire DDR3-2400 implique des latences plus faibles qu’un CAS de 9 sur de la DDR3-1333 : 9 ns dans le premier cas, 12 ns dans le second.
Pour limiter l’impact de ces latences, les mémoires actuelles permettent de lire et d’écrire plusieurs mots consécutivement (on parle de « burst ») sans que de nouvelles commandes soient envoyées. Par exemple, plutôt que de faire des accès mot par mot, les processeurs ont tendance à faire des accès en lecture de la longueur d’une ligne de cache, pour charger à chaque fois toute la ligne d’un coup. Par exemple, un processeur Haswell dont les lignes de cache font 64 octets fera quasi systématiquement des bursts de 8 cycles, permettant de récupérer 64 octets en une seule requête.
Par ailleurs, depuis l’arrivée de la SDRAM les barrettes de mémoire sont généralement dotés de plusieurs banques mémoire (2, 4 ou 8), c’est-à-dire plusieurs espaces mémoire pouvant fonctionner en parallèle : pendant qu’une banque est en train de traiter une requête, une nouvelle requête peut déjà être envoyée vers une autre banque. Là encore, ce principe permet de réduire les latences, en autorisant de l’activité sur le bus mémoire pendant qu’une requête est en cours de traitement, au lieu de laisser le bus inactif.
Et la DDR alors ?
Introduite quelques années après la SDRAM, la DDR-SDRAM se distingue par sa capacité à envoyer deux fois plus de données par cycle d’horloge sur le bus mémoire : une première série est envoyée sur le front montant du signal d’horloge, une seconde série sur le front descendant. En interne, la mémoire fonctionne toutefois toujours à la fréquence du bus, mais à chaque requête des données supplémentaires sont lues par anticipations : au lieu de lire uniquement un mot dans la ligne sélectionnée, ce sont deux mots consécutifs qui sont lus (le mot demandé et le mot suivant) et recopiés dans un buffer, une petite zone de mémoire fonctionnant à une fréquence bien plus rapide, qui va ainsi pouvoir restituer un mot à chaque demi-cycle de l’horloge externe. Avec une fréquence interne et externe de 200 MHz, on obtient alors un débit de 400 MT/s au lieu de 200 MT/s. À l’usage, le gain peut toutefois moins important, puisqu’il ne se réalise que si l’anticipation à fait mouche, en préchargeant bien les prochaines données réclamées par le CPU, ce qui est en pratique souvent le cas, puisque la plupart des CPU lisent les données par blocs de la taille d’une ligne de cache.
La DDR2 reprend ce principe, mais avec un buffer deux fois plus large, ce qui permet de doubler encore une fois le volume de données qui peut être transmis pour chaque cycle de l’horloge interne. Pour assurer ce transfert, la fréquence de l’horloge externe est doublée, tout en gardant le principe de l’envoi de deux mots par cycles. Avec des puces mémoire fonctionnant à 200 MHz en interne, on obtient ainsi une fréquence de bus de 400 MHz et un débit de 800 MT/s.
Enfin, l’actuelle DDR3 double encore une fois la taille du buffer et la fréquence externe, permettant d’atteindre une fréquence de bus de 800 MHz et un débit de 1600 MT/s avec des puces fonctionnant toujours à 200 MHz en interne. Ainsi, une requête burst qui s’exécutait en 8 cycles sur de la SDRAM à 200 MHz ne s’exécute en interne que sur un seul cycle sur de la DDR3-1600, les données étant ensuite transmises au processeur sur quatre cycles d’horloge externe.
Le futur…
Malgré son grand âge (les premières DRAM ont été commercialisées en 1970), la DRAM a sans doute encore de belles années devant elle. Plusieurs nouvelles technologies de mémoire ont bien été développées (Ferroelectric RAM, Resistive RAM, Magnetoresistive RAM, Phase-change RAM…), mais, si elles ont certains avantages par rapport à la DRAM, avec leur capacité à conserver les données mêmes sans alimentation, elles sont encore assez coûteuses et, pour la plupart, plus lentes que la DRAM, ce qui les cantonnerait plutôt au remplacement de la mémoire Flash pour le stockage.
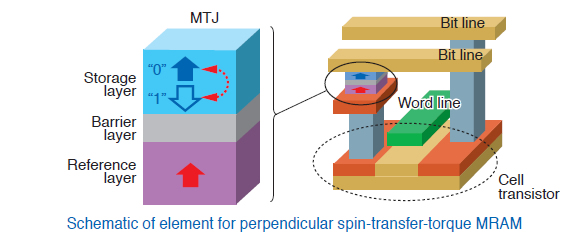 La mieux placée pour succéder à la DRAM semble être la MRAM, dont les performances sont déjà au niveau de ceux de la DRAM, voire un peu au dessus. Elle fonctionne sur un principe similaire, mais le condensateur y est remplacé par un élément dont la résistance électrique varie en fonction de son orientation magnétique. La lecture se fait donc en mesurant la résistance et l’écriture en forçant un changement d’orientation. Elle pourrait commencer à être produite en masse à l’horizon 2020.
La mieux placée pour succéder à la DRAM semble être la MRAM, dont les performances sont déjà au niveau de ceux de la DRAM, voire un peu au dessus. Elle fonctionne sur un principe similaire, mais le condensateur y est remplacé par un élément dont la résistance électrique varie en fonction de son orientation magnétique. La lecture se fait donc en mesurant la résistance et l’écriture en forçant un changement d’orientation. Elle pourrait commencer à être produite en masse à l’horizon 2020.
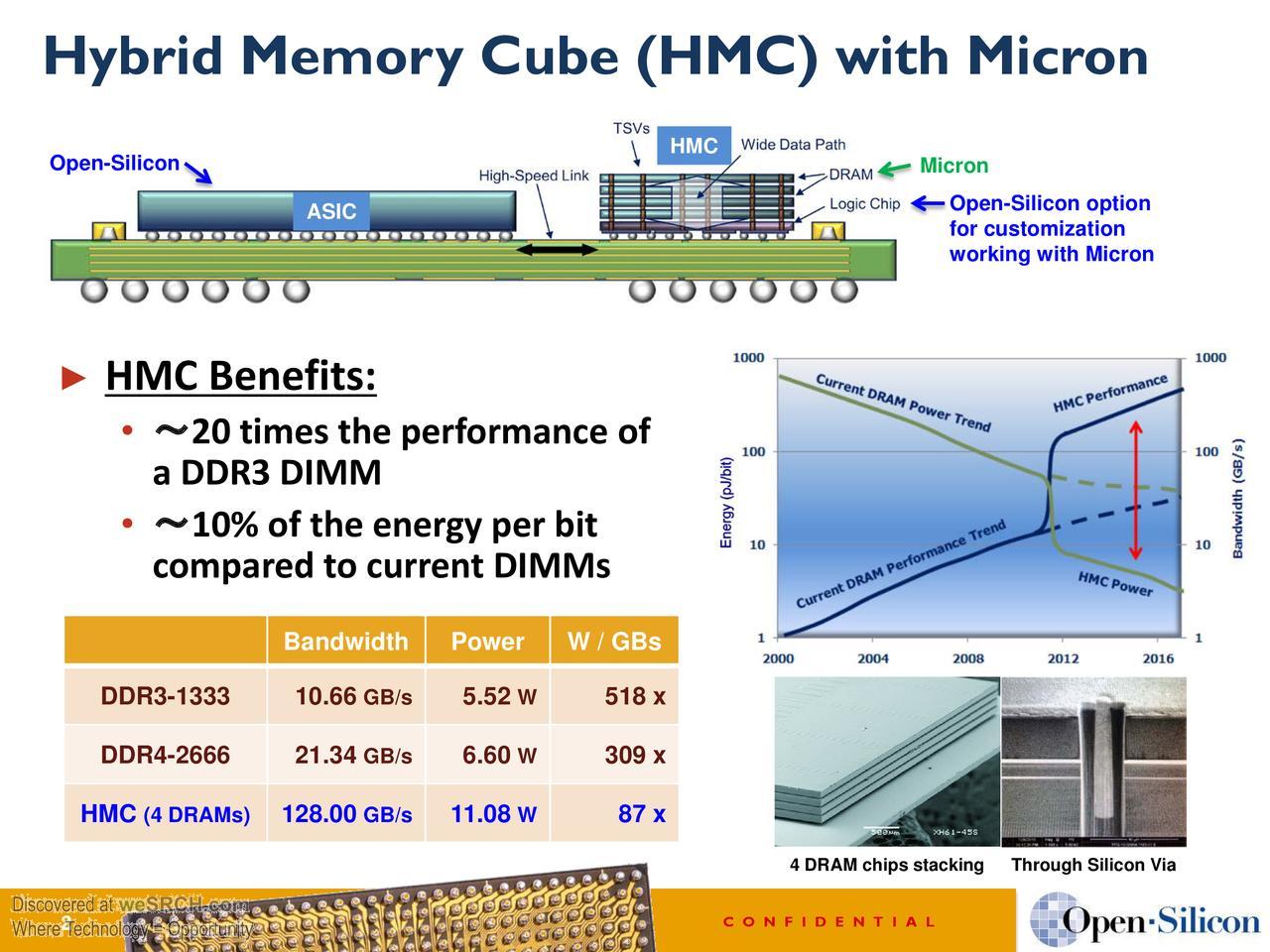 En attendant, la DRAM va continuer à être utilisée comme mémoire centrale, d’abord avec la DDR4 qui devrait être introduite dans moins d’un an, puis probablement avec l’Hybrid Memory Cube, une mémoire basée sur de la DRAM en interne (avec plusieurs puces de DRAM empilées dans un module HMC), mais dotés d’un contrôleur interne et d’une interface externe série permettant d’atteindre des performances largement supérieures à celles des interfaces DRAM classiques (jusqu’à 160 Go/s, et bientôt plus avec la HMC 2.0). La production en masse devrait débuter cette année, en ciblant d’abord principalement le monde des serveurs et des calculateurs, mais les RAM HMC pourraient aussi un jour débarquer dans nos PC.
En attendant, la DRAM va continuer à être utilisée comme mémoire centrale, d’abord avec la DDR4 qui devrait être introduite dans moins d’un an, puis probablement avec l’Hybrid Memory Cube, une mémoire basée sur de la DRAM en interne (avec plusieurs puces de DRAM empilées dans un module HMC), mais dotés d’un contrôleur interne et d’une interface externe série permettant d’atteindre des performances largement supérieures à celles des interfaces DRAM classiques (jusqu’à 160 Go/s, et bientôt plus avec la HMC 2.0). La production en masse devrait débuter cette année, en ciblant d’abord principalement le monde des serveurs et des calculateurs, mais les RAM HMC pourraient aussi un jour débarquer dans nos PC.
Super article, clair précis et ordonné, le top.
Petite méprise… « random » ne tient pas à la vitesse mais à la possibilité de faire indifféremment des accès en lecture ou écriture. Le terme est un faux-ami, en somme, il faudrait le traduire par « quelconque ».
Des accès séquentiels restent bien plus rapides que des accès (réellement) aléatoires et c’est d’autant plus vrai avec le prefetch.
Les RAM DDR3 stagnent depuis 2007…
Vive la HMC !
Cela dit, il faudra changer encore de config…^^
Juste un truc,
sous linux, je trouve que sur la mémoire seule, un petit « free » est plus lisible que top.
(free -m pour affichage en mega si vous voulez)
@wargre> Merci, je la connaissais pas celle là ^^
Tu as une source sur ce point ? Parce que partout où j’ai cherché, le random fait bien référence au caractère aléatoire des adresses accédées, pas au type des accès (voir par exemple cette page Wikipedia : https://en.wikipedia.org/wiki/Random_access )… Par contre les auteurs de cette page ont l’air de considérer qu’un disque dur rentre dans ce cas (vu qu’ils citent le CD en exemple), mais perso je suis pas tout a fait d’accord avec eux sur ce point ^^ D’abord parce que le temps d’accès augmente sensiblement en fonction de la distance entre la dernière adresse accédée et la suivante, ensuite parce que physiquement, le positionnement de la tête sur une piste est bien aléatoire, mais ensuite l’accès au secteur demandé nécessite de faire défiler la piste jusqu’à ce que le bon secteur passe sous la tête (idem pour le CD d’ailleurs, quand on saute une chanson sur un CD audio, une fois la tête placée au bon endroit faut attendre que le bon secteur passe au dessus de la tête pour lancer la lecture).
En gros, à l’exception du cas où tu fais un nouvel accès sur la même ligne, le temps d’accès est le même, quelque soit l’endroit où tu accèdes.
Et de mon point de vue le prefetch n’entre pas en ligne de compte à ce niveau : c’est un mécanisme « externe » à la zone de stockage qui précharge des données avant qu’elles soient demandées.
Et l’écart de performances entre le séquentiel et l’aléatoire sur la RAM n’a rien à voir avec ce qu’on peut observer sur un disque dur (où on peut atteindre un facteur 200 entre le débit en aléatoire et en séquentiel…).
Petite typo 😉
À l’usage, le gain peut toutefois moins important
L’accès aléatoire est bien entendu par opposition à l’accès séquentiel. À l’époque où ça a été défini, on avait clairement les bandes magnétiques et les cartes perforées en accès séquentiel, et les mémoires à tores de ferrites en accès aléatoire.
Pour moi, le disque dur est aussi à accès aléatoire — on peut accéder à n’importe quelle donnée en un temps borné qui est clairement moins que le temps de parcourir tout le disque.